Sortowanie bąbelkowe (ang. bubble sort)
- prosta metoda sortowania o złożoności czasowej  i pamięciowej
i pamięciowej  .
.
i pamięciowej .
Polega na porównywaniu dwóch kolejnych elementów i zamianie ich kolejności, jeżeli zaburza ona porządek, w jakim się sortuje tablicę. Sortowanie kończy się, gdy podczas kolejnego przejścia nie dokonano żadnej zmiany.
Ciąg wejściowy ![[4,2,5,1,7]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_tj0Juyu_OI4WHwGZ6bWDrJ9Km4syJ4WQRR8UFhrI6O9j_Yn6NMIx873uvTGcRBbrxK_WOPhYyc5UKsPJW39d-HjVnAUKQVEk6EwevtzBPb8hTObrqStLEbr5A-Lw98IZEMulkIrMNjCRnG3ykuNw=s0-d) . Każdy wiersz symbolizuje wypchnięcie kolejnego największego elementu na koniec ("wypłynięcie największego bąbelka"). Niebieskim kolorem oznaczono końcówkę ciągu już posortowanego.
. Każdy wiersz symbolizuje wypchnięcie kolejnego największego elementu na koniec ("wypłynięcie największego bąbelka"). Niebieskim kolorem oznaczono końcówkę ciągu już posortowanego.
. Każdy wiersz symbolizuje wypchnięcie kolejnego największego elementu na koniec ("wypłynięcie największego bąbelka"). Niebieskim kolorem oznaczono końcówkę ciągu już posortowanego.|
| |
|
| |
![[\underbrace {\color {Red}4,2}_{{4>2}},5,1,7]\rightarrow [2,\underbrace {\color {OliveGreen}4,5}_{{4<5}},1,7]\rightarrow [2,4,\underbrace {\color {Red}5,1}_{{5>1}},7]\rightarrow [2,4,1,\underbrace {\color {OliveGreen}5,7}_{{5<7}}]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_u9p8cAZUed-CCekVWHfyekvgWinTxCKTDR4fumMNiLd-TgGHT_5DqumehWMNzkdmVjjQmxXF28aQTAyqTrum0hVFwgwVV1S0YEJNsJREfDnCF1QLhT3sPc_fNqTQmoykYjqwGQEW80FJ2uSGq1ZA=s0-d)
![[\underbrace {\color {OliveGreen}2,4}_{{2<4}},1,5,{\color {Blue}7}]\rightarrow [2,\underbrace {\color {Red}4,1}_{{4>1}},5,{\color {Blue}7}]\rightarrow [2,1,\underbrace {\color {OliveGreen}4,5}_{{4<5}},{\color {Blue}7}]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_ulxrrkn50uGzysCI6EP-hyO6Srv1kqe0AhfWhM5UA4kp9LrmTp_lfi-rRdPkmFWgpiUJdGBDrwKcLlmlJk3C_-aan2Lm6PFgNNWY4VFWHTXa3Y0D2ZRkNUic0pRWy4skuvBKjYYPg0on9DPMXUvQ=s0-d)
![[\underbrace {\color {Red}2,1}_{{2>1}},4,{\color {Blue}5},{\color {Blue}7}]\rightarrow [1,\underbrace {\color {OliveGreen}2,4}_{{2<4}},{\color {Blue}5},{\color {Blue}7}]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_tPznaR_R8Mc-C3AaAek5_MYcxtcuMfs5xPIHjwPPM91g_BNZm_ahpPcIsCl2-NLDUGiOAnuL2BrZbg3UkycOspBDUBv-HoaKFa20cs5nizgIRRt2ciC98xFOygxk7rZmuPRw0omer4PLWyuPZm=s0-d)
![[\underbrace {\color {OliveGreen}1,2}_{{1<2}},{\color {Blue}4},{\color {Blue}5},{\color {Blue}7}]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_tvVHY8099nqvxD5p1iQGun4NeCYVbv8DbeqPkgnH5zDRRd7Efa8y9Tff9AD2W11WFhDpYz0z_HpiQd2JVXK1lZM7byBRYaoXL28qNy1cxdWT-LdvBQLpYKR54AJqYt_0_i6nRE8yI9K66vfgJpwg=s0-d)

Sortowanie przez wybieranie
- jedna z prostszych metod sortowania o złożoności O(n2). Polega na wyszukaniu elementu mającego się znaleźć na zadanej pozycji i zamianie miejscami z tym, który jest tam obecnie. Operacja jest wykonywana dla wszystkich indeksów sortowanej tablicy.
Algorytm przedstawia się następująco:
- wyszukaj minimalną wartość z tablicy spośród elementów od i+1 do końca tablicy
- zamień wartość minimalną, z elementem na pozycji i
Gdy zamiast wartości minimalnej wybierana będzie maksymalna, wówczas tablica będzie posortowana od największego do najmniejszego elementu.
Algorytm jest niestabilny. Przykładowa lista to: [2a,2b,1] → [1,2b,2a] (gdzie 2b=2a)

Sortowanie przez zliczanie
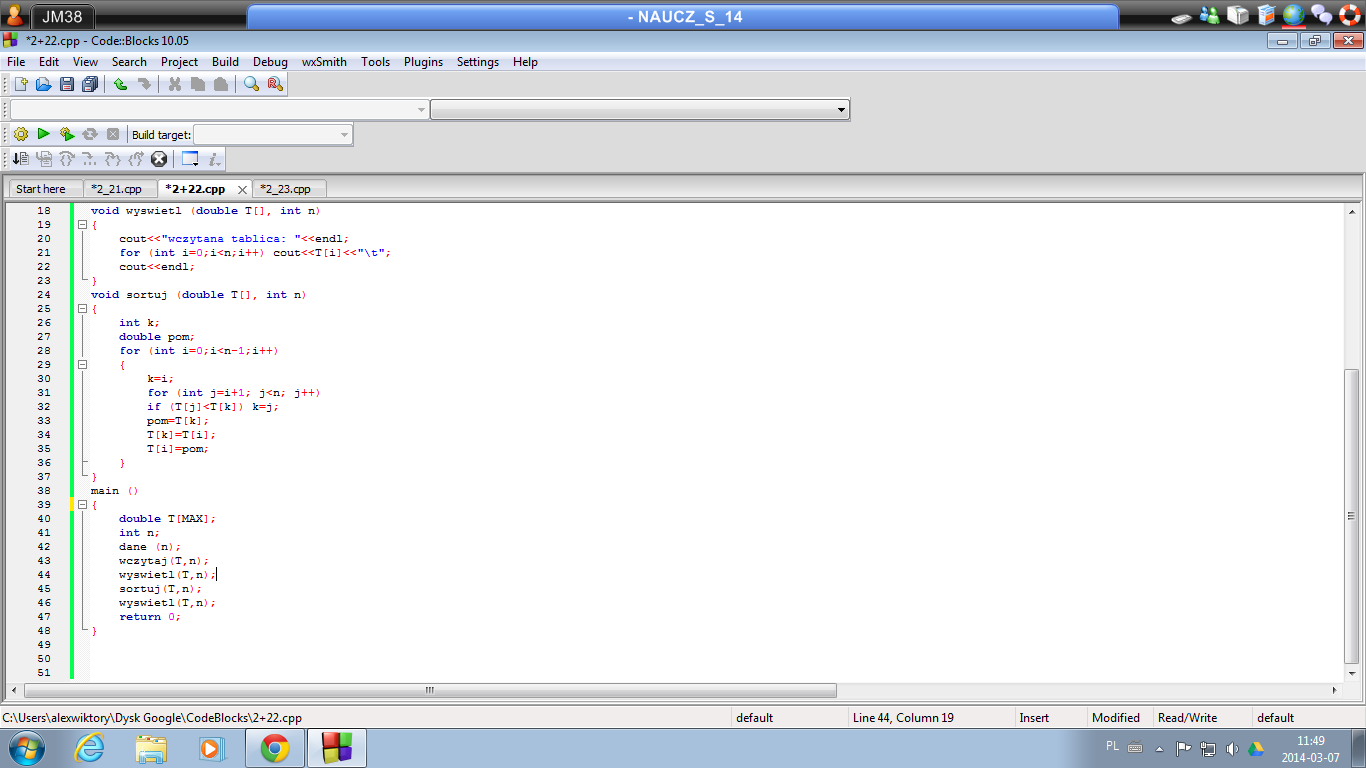
– metoda sortowania danych, która polega na sprawdzeniu ile wystąpień kluczy mniejszych od danego występuje w sortowanej tablicy.
Algorytm zakłada, że klucze elementów należą do skończonego zbioru (np. są to liczby całkowite z przedziału 0..100), co ogranicza możliwości jego zastosowania.


Sortowanie przez wstawianie (ang. Insert Sort, Insertion Sort)
- jeden z najprostszych algorytmów sortowania, którego zasada działania odzwierciedla sposób w jaki ludzie ustawiają karty - kolejne elementy wejściowe są ustawiane na odpowiednie miejsca docelowe. Jest efektywny dla niewielkiej liczby elementów, jego złożoność wynosi O(n2)[1]. Pomimo tego, że jest znacznie mniej wydajny od algorytmów takich jak quicksort czyheapsort, posiada pewne zalety:
- jest wydajny dla danych wstępnie posortowanych
- jest wydajny dla zbiorów o niewielkiej liczebności
- jest stabilny
Schemat działania:
- Utwórz zbiór elementów posortowanych i przenieś do niego dowolny element ze zbioru nieposortowanego.
- Weź dowolny element ze zbioru nieposortowanego.
- Wyciągnięty element porównuj z kolejnymi elementami zbioru posortowanego póki nie napotkasz elementu równego lub elementu większego (jeśli chcemy otrzymać ciąg niemalejący) lub nie znajdziemy się na początku/końcu zbioru uporządkowanego.
- Wyciągnięty element wstaw w miejsce gdzie skończyłeś porównywać.
- Jeśli zbiór elementów nieuporządkowanych jest niepusty wróć do punkt 2.
Sortowanie kubełkowe (ang. bucket sort)
– jeden z algorytmów sortowania. Jest on najczęściej stosowany, gdy liczby w zadanym przedziale są rozłożone jednostajnie, ma on wówczas złożoność Θ(n). W przypadku ogólnym pesymistyczna złożoność obliczeniowa tego algorytmu wynosi O(n²).
Pomysł takiego sortowania podali po raz pierwszy w roku 1956 E. J. Issac i R. C. Singleton.
Schemat działania:
- Podziel zadany przedział liczb na n podprzedziałów (kubełków) o równej długości.
- Przypisz liczby z sortowanej tablicy do odpowiednich kubełków.
- Sortuj liczby w niepustych kubełkach.
- Wypisz po kolei zawartość niepustych kubełków.
Zazwyczaj przyjmuje się, że sortowane liczby należą do przedziału od 0 do 1. Jeśli tak nie jest, to można podzielić każdą z nich, przez największą możliwą (jeśli znany jest przedział) lub wyznaczoną. Należy tu jednak zwrócić uwagę, że wyznaczanie największej możliwej liczby w tablicy m-elementowej ma złożoność obliczeniową O(m).
- #include <iostream>
- using namespace std;
- int main(int argc, char *argv[])
- {
- int max,min,count,*t,*t2;
- char exit;
- cout << "Ile liczb chcesz posortowac?";
- cin >> count;
- t = new int[count]; // Stworzenie tablicy dla danych wejściowych
- for(int i=0;i<count;i++){ // Podanie liczb do sortowania
- cout << "Podaj " << i+1 << " liczbe: ";
- cin >> t[i];
- }
- max = t[0];
- min = t[0];
- for(int i=0;i<count;i++){ // Znalezienie najmniejszej i największej liczby
- max = max<t[i]?t[i]:max;
- min = min>t[i]?t[i]:min;
- }
- t2 = new int[max-min+1]; // Stworzenie tablicy z kubełkami
- for(int i=0;i<=count;i++) t2[t[i]-min] += 1; // Wypełnianie kubełków
- cout << "Kolejność rosnąca: ";
- for(int i=0;i<max-min+1;i++) if(t2[i]>0) for(int j=1;j<=t2[i];j++) cout << i+min << " "; // Wypisanie wyniku
- cin >> exit;
- return 0;
- }
Brak komentarzy:
Prześlij komentarz